User Guide¶
This guide will give an overview of the available modules and functionalities of the skpro package.
For further details you may explore the API documentation.
Note
skpro uses many of scikit-learn’s building principles and conventions. If you aren’t familiar with the scikit-learn package you may read its basic tutorial.
Overview¶
The figure below gives an overview about central elements and concepts of skpro and how it extends the scikit-learn toolbox. To understand skpro, it is firstly helpful to quickly review scikit-learn’s classical prediction workflow, particularly its seminal Estimator object. In scikit-learn, an Estimator object represents a certain prediction strategy (e.g. Linear regression), that can be fitted using the fit(X, y) function. The fitted estimator can then be used to obtain the predictions on new data using the predict(X) method. Finally, the predicted values can be compared with the actual targets using one of the available classical loss functions.
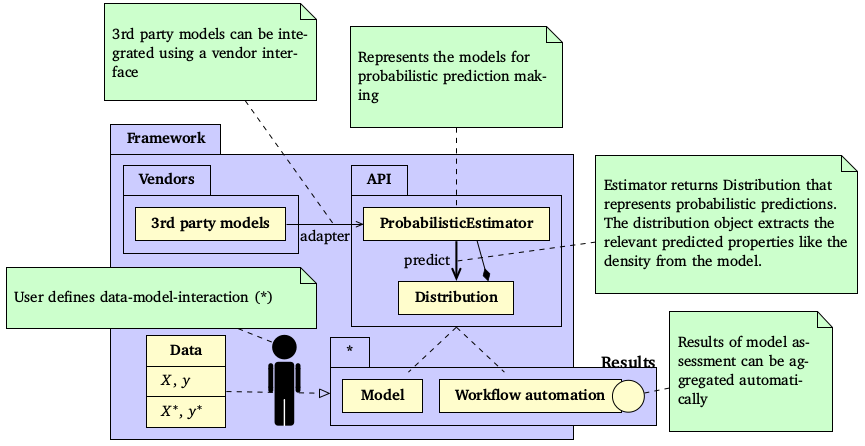
Overview of the skpro API: All models are represented in as a probablistic estimator returning a distribution object that exhibits properties like the predicted density function etc. The user can define a workflow involving different models and datasets while the results of a model assessment is aggregated automatically.
skpro seeks to replicate this general pattern and introduces the ProbabilisticEstimator class that encapsulates the
probabilistic prediction models. Like the Estimator class it offers a fit and predict method but returns a probability distribution as prediction (Distribution class). The returned distribution objects provide methods to obtain relevant distribution properties, for example the distribution’s probability density function (y_pred.pdf(x)).
The predictions obtained from skpro’s estimators are hence of a genuine probabilistic kind that represent predicted probability distributions for each data point. For example, if predictions for a vector X of length k are obtained, the returned y_pred object represents k predicted distributions. y_pred[i] therefore provides access to the point prediction (e.g. mean) of the i-th distribution, y_pred.std() will return a vector of length k that contains the standard deviations of the predicted distribution, and so forth. In many cases, such as plotting and error calculation, the distributions objects can thus be handled like scikit’s commonly returned prediction vectors.
To evaluate the accuracy of the predicted distributions, skpro provides probabilistic loss metrics. To calculate the loss between prediction and the true target values, you can choose from a variety of available functions in the skpro.metrics module. In the default setting, all loss functions return the averaged loss of the sample. If you’d like to obtain the point-wise loss instead, set sample=False. You can also obtain the confidence interval of the loss by setting return_std to True. For a detailed documentation of the metrics package read the API documentation.
Available prediction strategies¶
How can probabilistic prediction models be learned, specifically strategies that predict probability distributions? skpro offers a variety of strategies both from the frequentist and Bayesian domain. Please continue to read about strategies of interest below:
- Baseline strategies, for instance a kernel density estimation on the labels
- Parametric estimation, that estimates parameters of the predicted distributions
- integrations with other vendor packages such as
PyMC3
The figure below shows an overview of the skpro’s base API which implements the different prediction strategies. For a full documentation you may read the respective module documention.
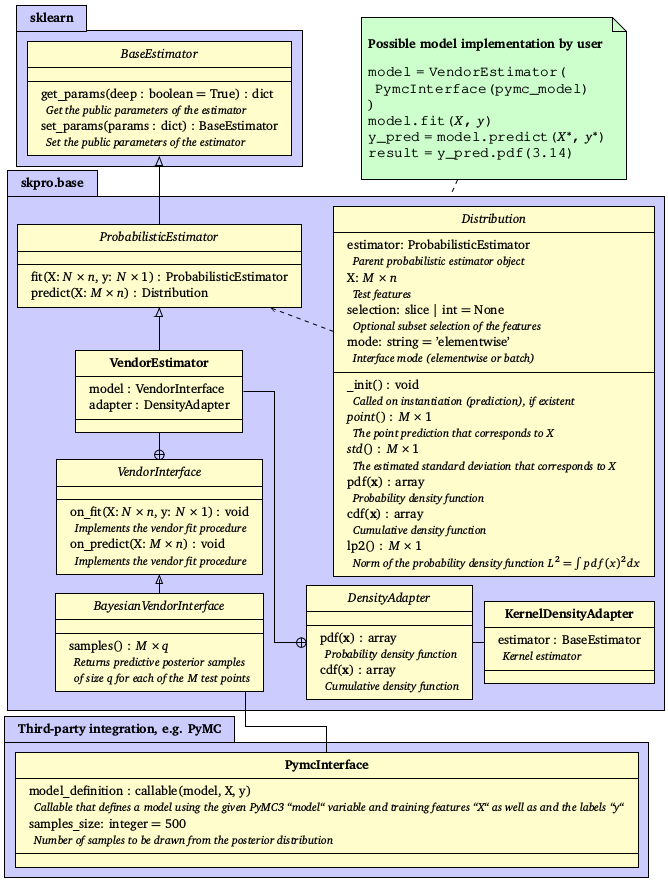
Overview of the framework’s core API where abstract classes are denoted in italic font and inheritance and dependence are indicated by arrows: The seminal probabilistic estimator object directly inherits from scikit-learn’s base estimator object and thus implements the fit-predict logic that produce probabilistic predictions in form of a distribution object. A vendor estimator allows for the integration of 3rd party models such as the Bayesian PyMC prediction algorithms.
Advanced topics¶
As mentioned earlier, skpro comes with an advanced logic for workflow automation. You may also want to read about meta-modelling strategies and the integration of custom models.
Help and support¶
If you have question, feel free to open an issue on our GitHub page.