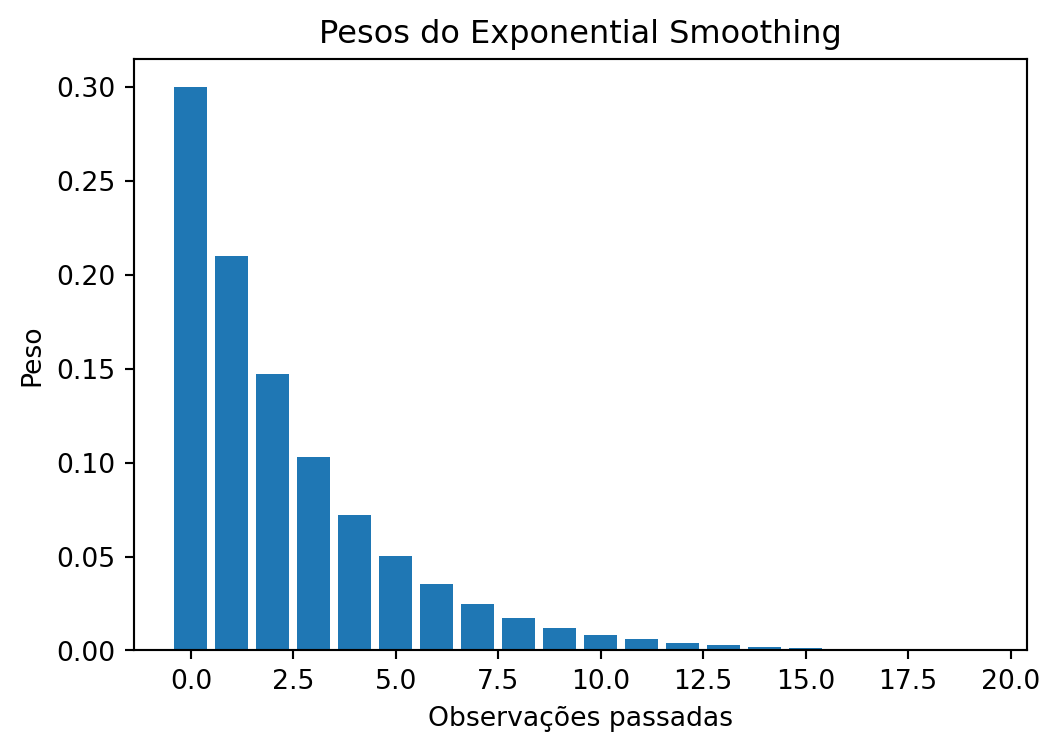
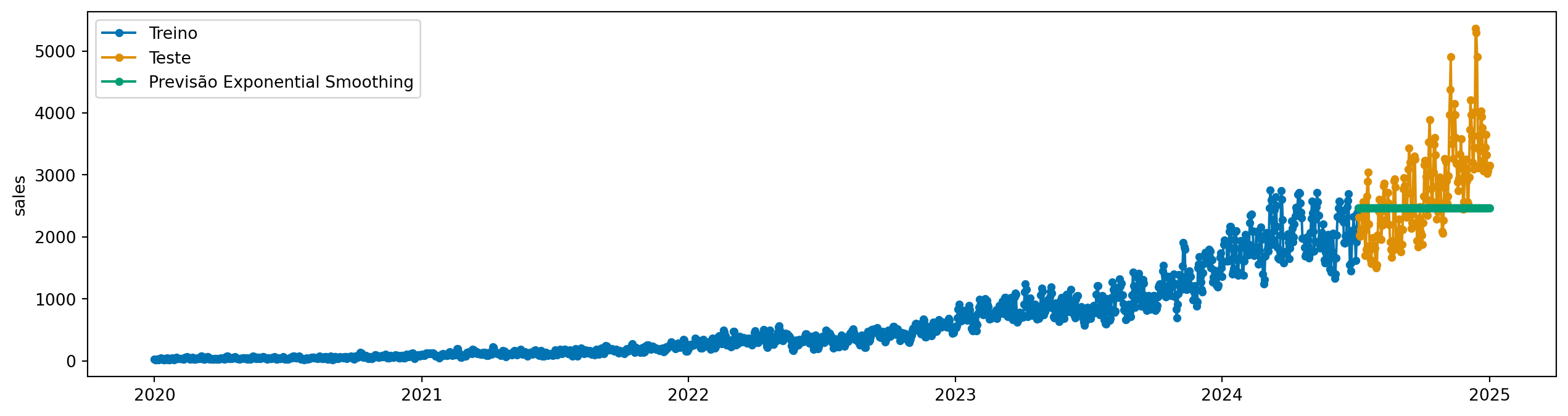
Ele basicamente atribui o mesmo peso para todas as observações passadas. Mas, intuitivamente, faz mais sentido dar mais peso para as observações mais recentes, e menos peso para as observações mais antigas.
O exponential smoothing faz exatamente isso. Ele atribui pesos decrescentes para observações mais antigas. O peso da observação decresce exponencialmente segundo um fator \(0 < \alpha < 1\)(Hyndman and Athanasopoulos 2018):
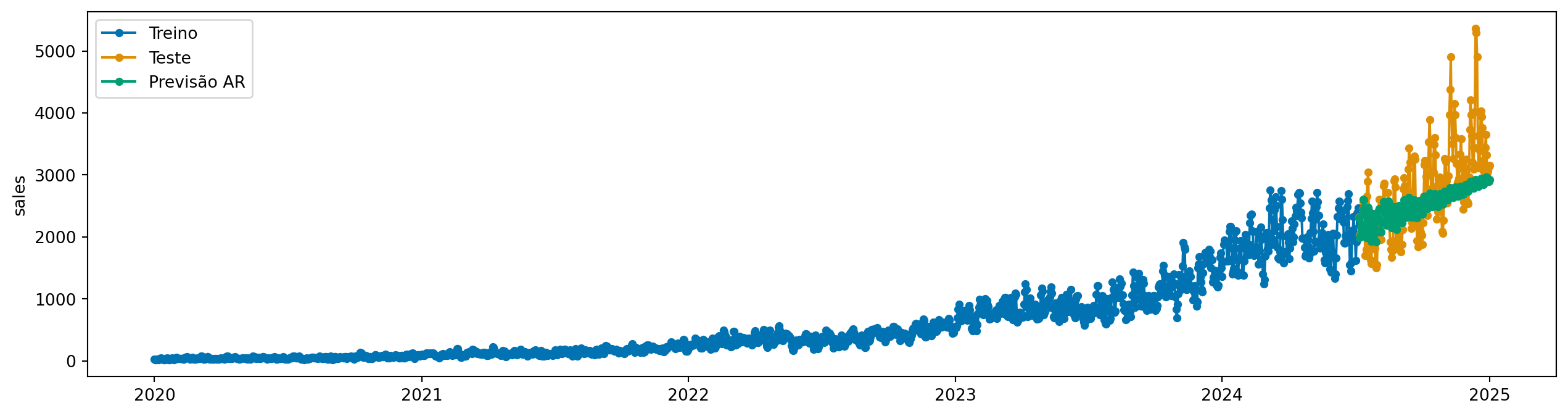
Modelos autoregressivos (AR) são modelos que prevem o valor atual de uma série temporal como uma combinação dos valores passados. O modelo AR(p) usa os últimos p valores para fazer a previsão:
Um modelo auto-regressivo mais complexo é o ARIMA, que combina autoregressão (AR), média móvel (MA) e diferenciação integrada (I) para lidar com séries temporais não estacionárias. Não vamos estudar o ARIMA aqui pois envolve conceitos mais avançados, mas temos ele disponível no sktime, sktime.forecasting.arima.ARIMA.
4.3 STL: dividir e conquistar
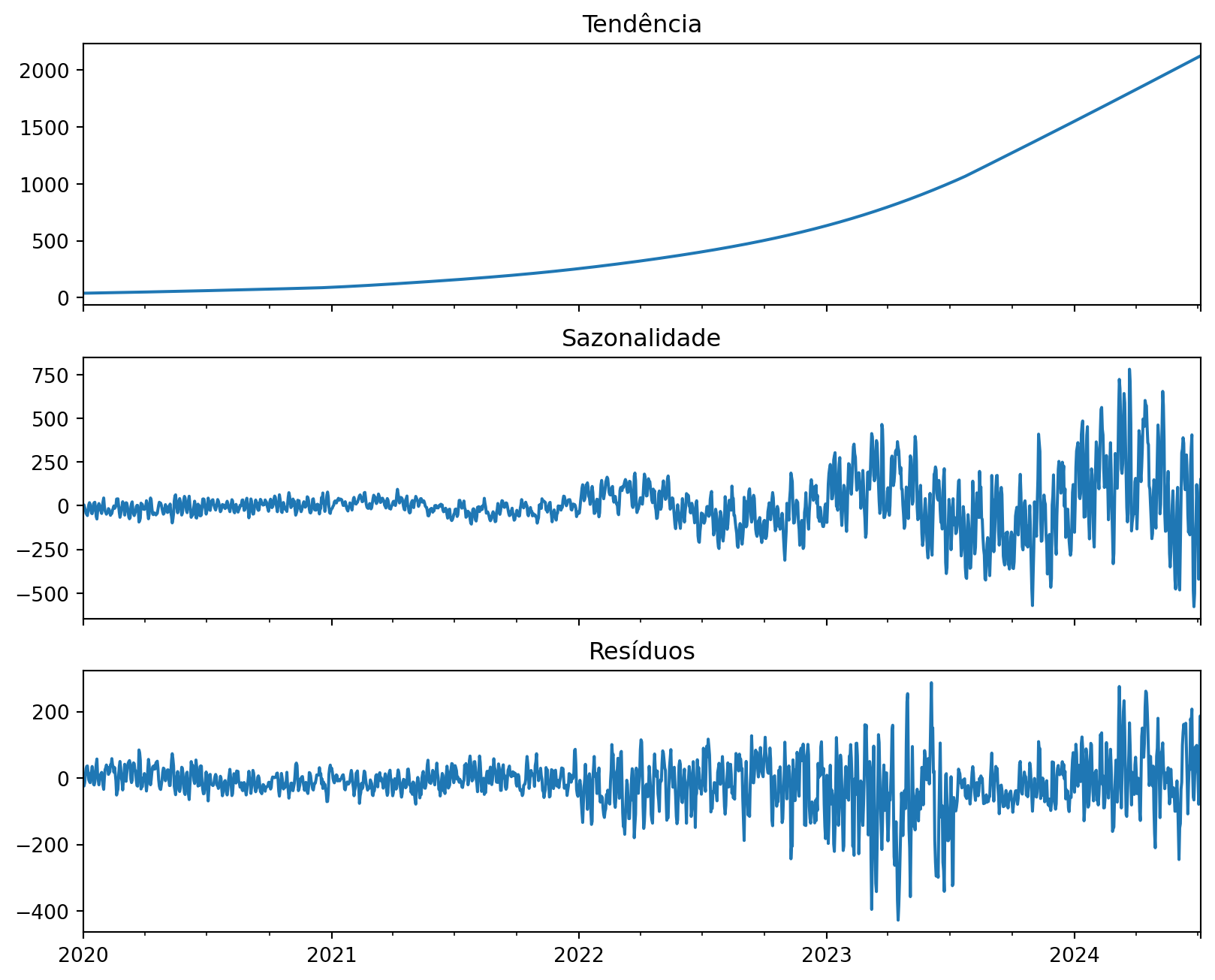
Sabemos que séries temporais podem ser decompostas em componentes de tendência, sazonalidade e resíduos. O modelo STL (Seasonal and Trend decomposition using Loess) é uma técnica que permite fazer essa decomposição de forma robusta.
Temos no sktime o STLTransformer, que permite fazer a decomposição STL:
from sktime.transformations.series.detrend import STLTransformerstl = STLTransformer(sp=365)stl.fit(y_train)
STLTransformer(sp=365)
Please rerun this cell to show the HTML repr or trust the notebook.
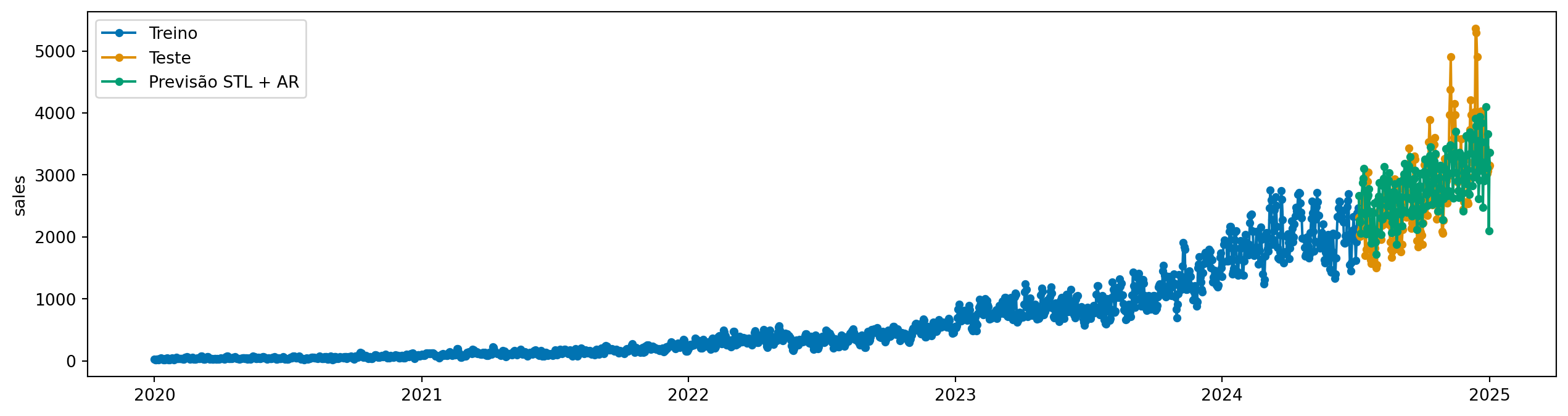
Uma possibilidade, uma vez que temos os diferentes componentes, é modelar cada componente separadamente e depois combinar as previsões. O sktime tem o STLForecaster, que faz exatamente isso: