Como séries temporais possuem uma ordem temporal, a sua própria história tem poder preditivo muito forte. No entanto, em alguns casos, apenas a história não é suficiente para fazer previsões precisas.
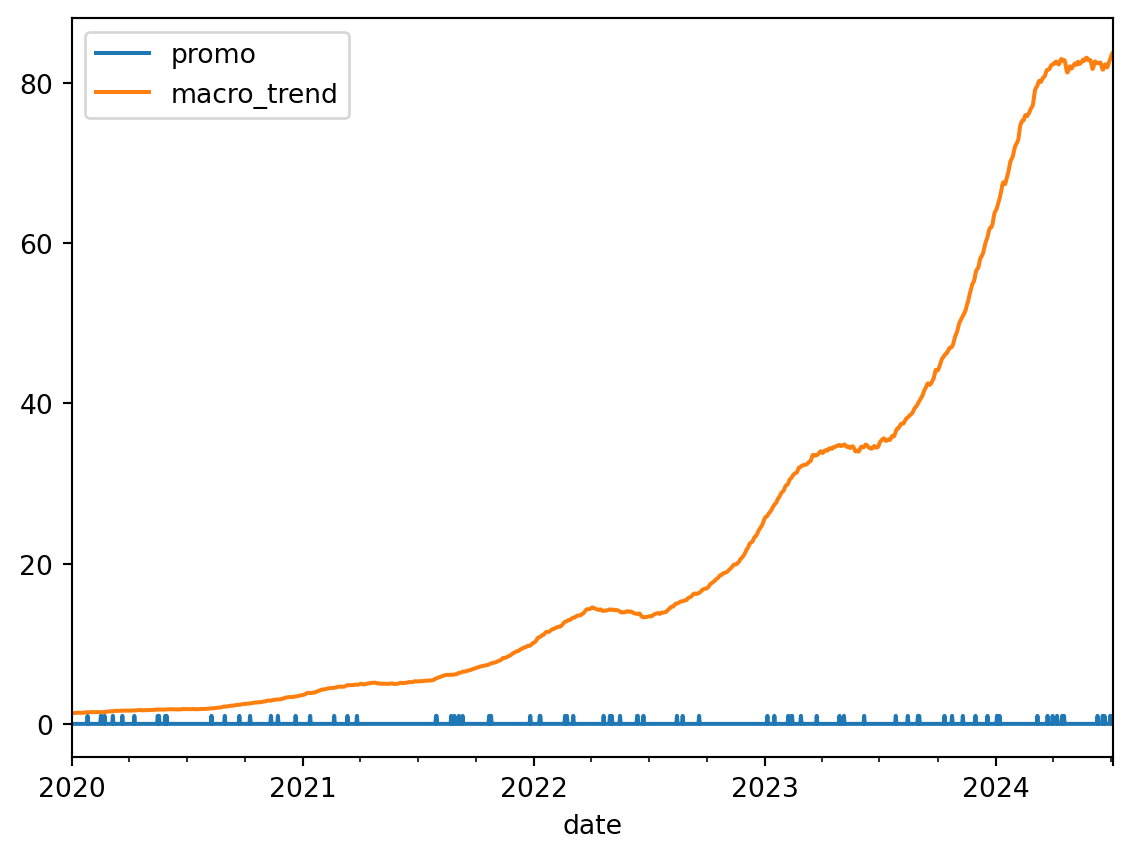
Por exemplo, em vendas de varejo, fatores como promoções, feriados e eventos sazonais podem impactar significativamente as vendas.
Agora, vamos ver como usar variáveis exógenas em modelos de séries temporais com sktime, as famosas “features”.
A interface é sempre a mesma, vamos ver que a diferença é o uso do parâmetro X nos métodos fit e predict.
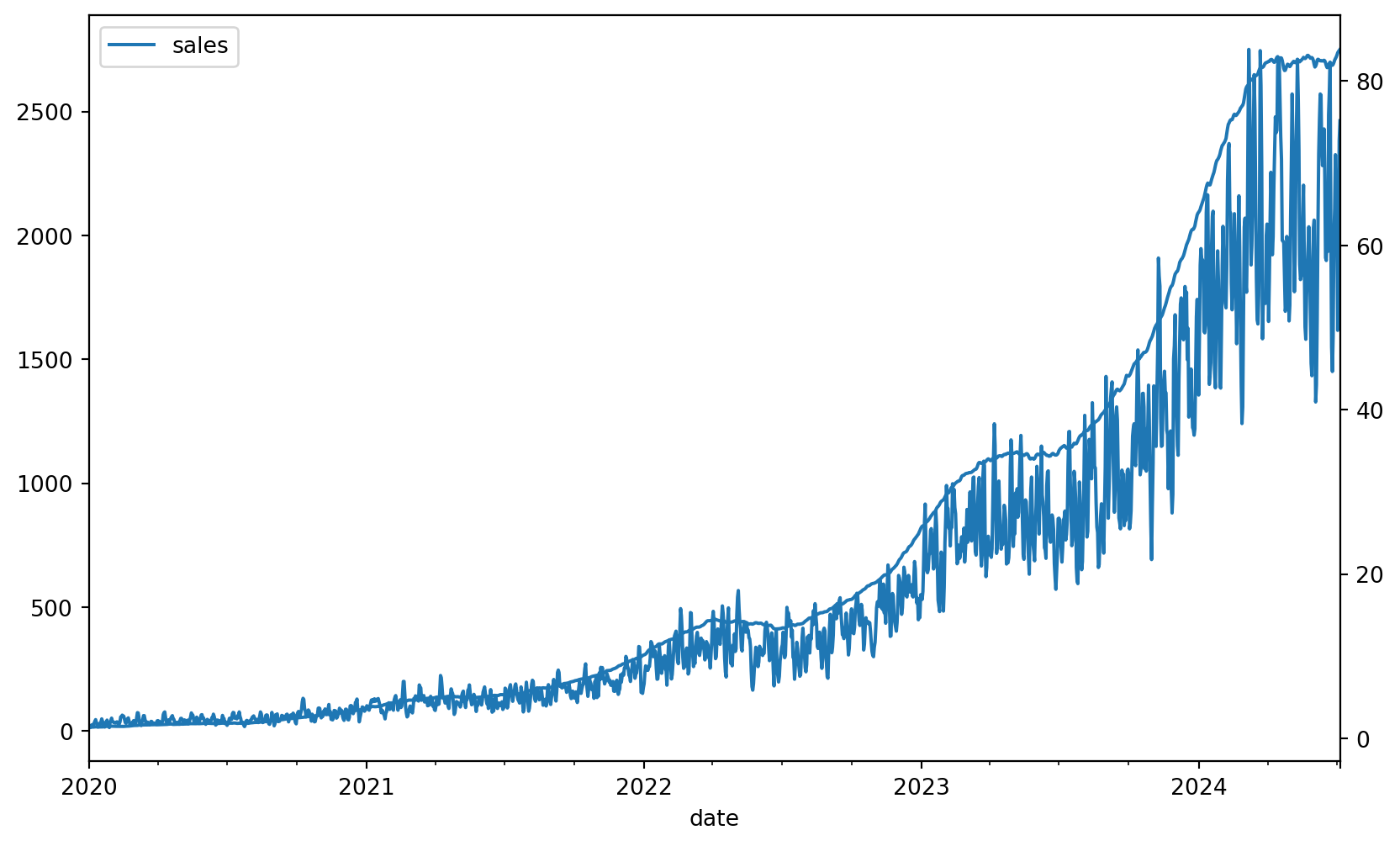
Usaremos os mesmos dados de varejo sintético dos exemplos anteriores. Agora, teremos também X_train e X_test, que são as variáveis exógenas.
Nem todos modelos suportam variáveis exógenas. Para ver uma lista de possibilidades, podemos usar a função all_estimators do sktime.
from sktime.registry import all_estimatorsall_estimators("forecaster", filter_tags={"capability:exogenous": True}, as_dataframe=True)
name
object
0
ARDL
<class 'sktime.forecasting.ardl.ARDL'>
1
ARIMA
<class 'sktime.forecasting.arima._pmdarima.ARI...
2
AutoARIMA
<class 'sktime.forecasting.arima._pmdarima.Aut...
3
AutoEnsembleForecaster
<class 'sktime.forecasting.compose._ensemble.A...
4
AutoREG
<class 'sktime.forecasting.auto_reg.AutoREG'>
...
...
...
77
UpdateEvery
<class 'sktime.forecasting.stream._update.Upda...
78
UpdateRefitsEvery
<class 'sktime.forecasting.stream._update.Upda...
79
VARMAX
<class 'sktime.forecasting.varmax.VARMAX'>
80
VECM
<class 'sktime.forecasting.vecm.VECM'>
81
YfromX
<class 'sktime.forecasting.compose._reduce.Yfr...
82 rows × 2 columns
6.1 Tipos de Variáveis Exógenas
Antes de prosseguirmos, vamos separar as variáveis exógenas em dois tipos:
Variáveis exógenas com valores futuros conhecidos: São variáveis cujos valores futuros já são conhecidos no momento da previsão. Variáveis indicadoras (dummies) para feriados ou eventos especiais, bem como recursos de sazonalidade, são exemplos comuns desse tipo de variável.
Variáveis exógenas com valores futuros desconhecidos: São variáveis cujos valores futuros não são conhecidos para o horizonte de previsão. Por exemplo, se quisermos incluir indicadores econômicos que ainda não foram divulgados, devemos tratá-los como variáveis exógenas de valor futuro desconhecido.
Nesse último cenário, para realizar a previsão, existem três opções: 1. Prever os valores futuros das variáveis exógenas usando um modelo separado (ou o mesmo modelo, se ele permitir) e usar essas previsões como entrada para o modelo principal de previsão. 2. Usar um valor de preenchimento (por exemplo, o último valor conhecido) para as variáveis exógenas de valor futuro desconhecido durante a previsão. 3. Usar valores defasados (lags) das variáveis exógenas como características (features), o que pode ser útil se o modelo conseguir aprender com os valores passados dessas variáveis.
6.2 Usando variáveis exógenas com sktime
Vamos usar AutoREG como modelo base para nosso exemplo de vairáveis exógenas. Primeiramente, vamos supor que conhecemos a variável macro_trend no futuro
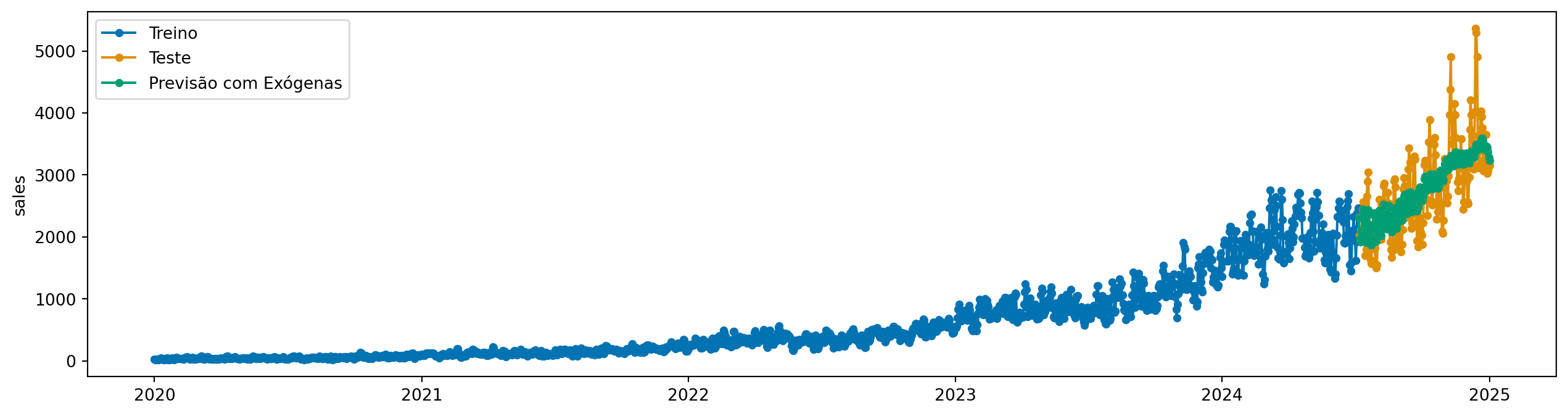
from sktime.forecasting.auto_reg import AutoREGmodel = AutoREG(lags=30)model.fit(y_train, X=X_train)y_pred = model.predict(fh=y_test.index, X=X_test)
plot_series(y_train, y_test, y_pred, labels=["Treino", "Teste", "Previsão com Exógenas"])
Fácil, no caso que conhecemos a variável exógena no futuro, basta passar X em fit e predict.
Antes de avançar, é importante revisar que os transformadores com fit e transform também podem ser aplicados a variávei exógenas! Inclusive, podemos fazer pipelines compostos de várias etapas de preprocessamento de exógenas. Isso será importante para os próximos exemplos.
6.3 Variável observada, mas desconhecida no futuro
Vamos eliminar a variável macro_trend do conjunto de teste, para simular o cenário onde não conhecemos o valor futuro dessa variável.
import numpy as npX_test_missing = X_test.copy()X_test_missing["macro_trend"] = np.nan
6.3.1 Solução 1: Prever a variável exógena
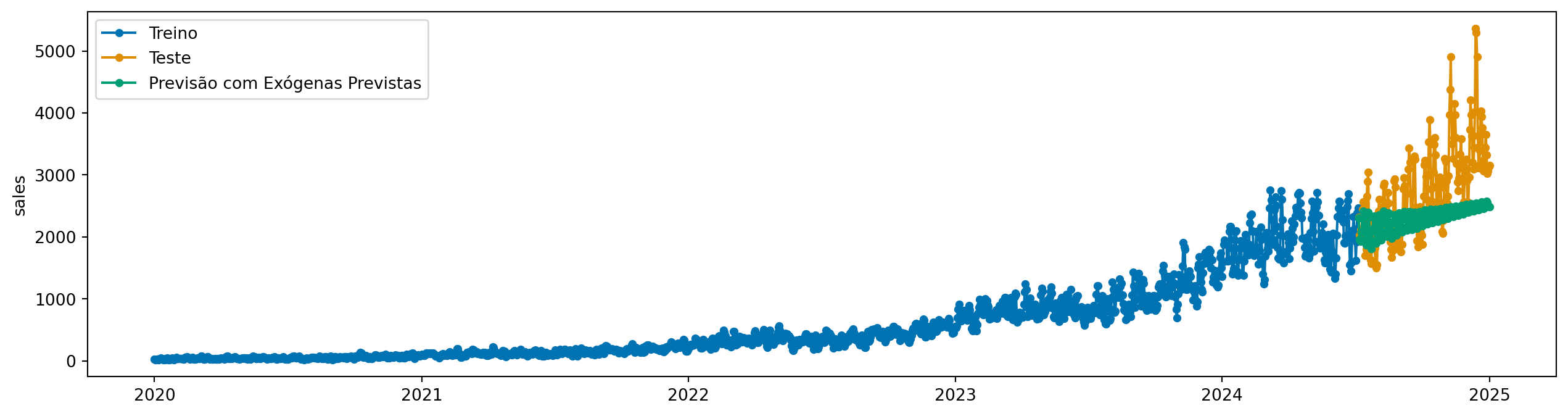
Agora, vamos supor que não sabemos o valor futuro de macro_trend. Nesse caso, podemos criar um modelo separado para prever macro_trend e usar essa previsão como entrada para o modelo principal.
Sktime possui uma funcionalidade pronta para isso: um forecaster chamado ForecastX. Ele é composto de dois modelos, um para a variável exógena, e outro para o alvo principal.
Aqui, o forecaster necessita que o horizonte de previsão (fh) seja passado já na etapa de fit.
from sktime.forecasting.compose import ForecastXmodel = ForecastX( forecaster_y=AutoREG(lags=30), forecaster_X=AutoREG(lags=30),)fh = [i for i inrange(1, len(y_test) +1)]model.fit(y_train, X=X_train, fh=fh)y_pred_case1 = model.predict(X=X_test_missing)
plot_series(y_train, y_test, y_pred_case1, labels=["Treino", "Teste", "Previsão com Exógenas Previstas"])
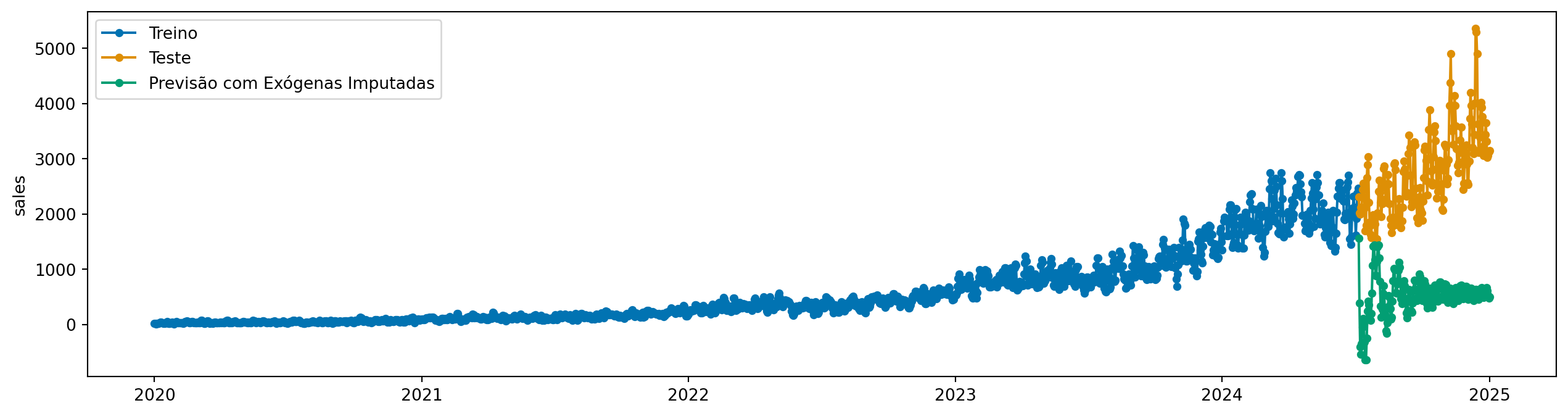
6.3.2 Solução 2: Usar valor de preenchimento (imputação)
Para essa solução, vamos usar transformadores para preencher os valores faltantes na variável exógena. Aqui, usaremos o Imputer do sktime, que suporta variáveis exógenas.
from sktime.transformations.series.impute import Imputerimputer = Imputer(method="mean")imputer.fit(X_train)# Agora imputamosX_test_imputed = imputer.transform(X_test_missing)X_test_imputed.tail()
promo
macro_trend
date
2024-12-28
0.0
22.809251
2024-12-29
0.0
22.809251
2024-12-30
0.0
22.809251
2024-12-31
1.0
22.809251
2025-01-01
0.0
22.809251
Para usar preprocessamento de exógenas + forecasting, podemos usar a composição ForecastingPipeline.
Nossa previsão não ficou boa. Claro! A variável exógena possui uma tendência - que naturalmente faz com que a imputação do ultimo valor ou a média não funcione bem. A solução ótima varia de caso para caso.
Tip
Dica: Podemos também usar o operador ** como atalho para criar pipelines de variáveis exógenas.
model = Imputer(method="mean") ** AutoREG(lags=30)
Note a diferença do que aprendemos para criar pipelines com transformações na variável target, que usam * como operador. Claramente, podemos fazer composições mais complexas, como:
model = Imputer(method="mean") ** (Differencer() * AutoREG())
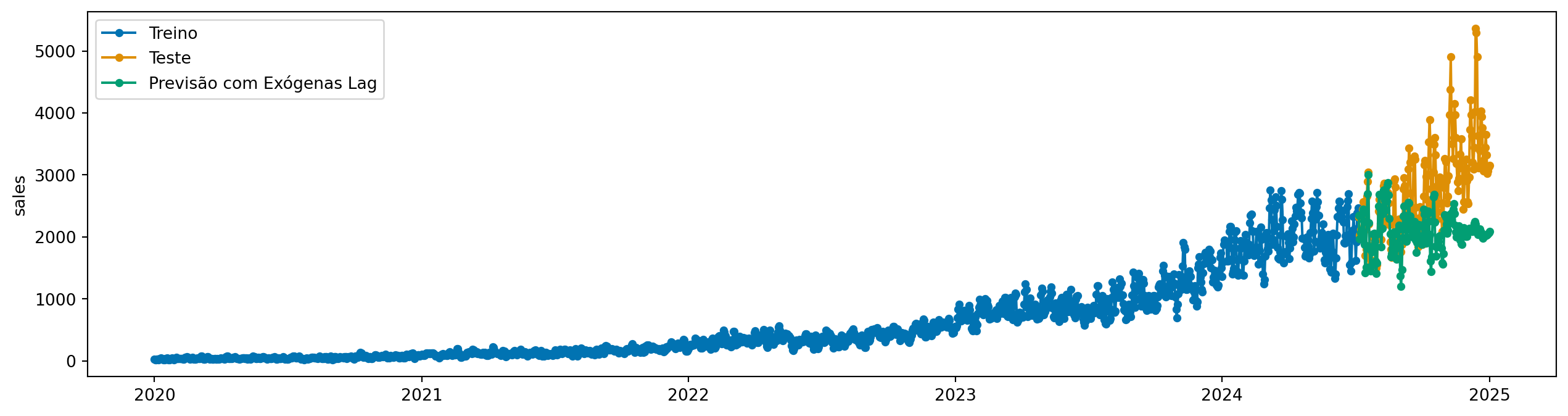
6.3.3 Solução 3: Usar valores defasados (lags) da variável exógena
Outra opção é criar versões defasadas das variáveis exógenas e usá-las como features.
Para isso, podemos usar o transformador Lag do sktime. Ao utilizar defasagens (lags), surgem dois desafios principais:
O aparecimento de valores NaN, que muitos modelos de previsão não conseguem tratar.
O número de variáveis exógenas pode aumentar significativamente, o que pode levar a overfitting ou, no caso do nosso conjunto de dados, a um número de features maior que o número de amostras — o que pode gerar erros no processo de ajuste (fitting).
Para lidar com isso, no exemplo abaixo utilizamos um TransformerPipeline que realiza as seguintes etapas:
Seleção de variáveis: executa uma seleção das variáveis exógenas, mantendo apenas as mais relevantes.
Defasagem: aplica o transformador Lag para criar versões defasadas das variáveis exógenas.
Imputação: usa o transformador Imputer para preencher os valores NaN criados pelo processo de defasagem. Neste caso, é usado o método backfill (preenchimento a partir de valores posteriores).
from sktime.transformations.compose import TransformerPipelinefrom sktime.transformations.series.feature_selection import FeatureSelectionfrom sktime.transformations.series.impute import Imputerfrom sktime.transformations.series.lag import Lagfrom sktime.transformations.series.subset import IndexSubsettransformer_pipeline = TransformerPipeline( steps=[ ("lag", Lag(lags=list(range(1, 180+1)))), # Cria lags 3 e 4 ("subset", IndexSubset()), # Seleciona apenas macro_trend ("impute", Imputer(method="backfill", value=0)), # Imputa valores NaN ("feature_selection", FeatureSelection()), # Seleciona features ])